交接:在 Windows 上實現 ResNet 與 SENet 實驗
- 本篇的所有故事都發生在
C:/Projects/caffe/ResNet/當中。 - 桌面有一個名為
caffe-windows-ms的資料夾,千萬不要更動或刪除!因為在跑 SENet 時需要特殊的網路結構,這結構在一般的 caffe 安裝包裡都沒有,所以必須透過 Visual Studio 改造與編譯;而這個資料夾裡放的caffe.exe就是最終編譯好的版本。如果不小心刪掉,請去 SENet 的 Github 下載特殊的 caffe 結構,並爬文「如何在 windows 下使用 Visual Studio 編譯 caffe」。
訓練篇
在C:/Projects/caffe/ResNet/目錄中,包含了 ResNet 101 層與 SENet 101 層的所有訓練與測試檔案。
因為 ResNet 與 SENet 並不像 YOLO 具備 Detection 的功能,所以我們在進行實驗時,必須先以「手動剪裁」的方式,把資料集當中的「目標物」剪裁出來進行訓練與測試,而不是直接將整張影像丟進去。
Step 1: 準備訓練資料集
- 在
train資料夾中,放入所有訓練用的影像檔案,從1.jpg開始連續編號。 - 接著,使用
txt_generator.py檔案,產生訓練用的 label 檔案train.txt,一樣放在train資料夾中。 - 最後,雙擊
Step1_create_train_lmdb.bat檔案,在lmdb資料夾中產生img_train_lmdb資料夾。
Step 2: 準備測試資料集
- 在
test資料夾中,一樣放入所有測試用的影像檔案,從1.jpg開始連續編號。 - 接著,同樣使用
txt_generator.py檔案,產生測試用的 label 檔案test.txt,放在test資料夾中。 - 最後,雙擊
Step2_create_test_lmdb.bat檔案,在lmdb資料夾中產生img_test_lmdb資料夾。
Step 3: 計算訓練影像均值
- 當我們產生
img_train_lmdb資料夾之後,就可以直接雙擊Step3_compute_image_mean.bat檔案,在lmdb資料夾中產生mean.binaryproto檔案。
Step 4: 訓練設定
ResNet 與 SENet 的網路結構檔案,分別為ResNet_101_train.prototxt與SE-ResNet_101_train.prototxt。
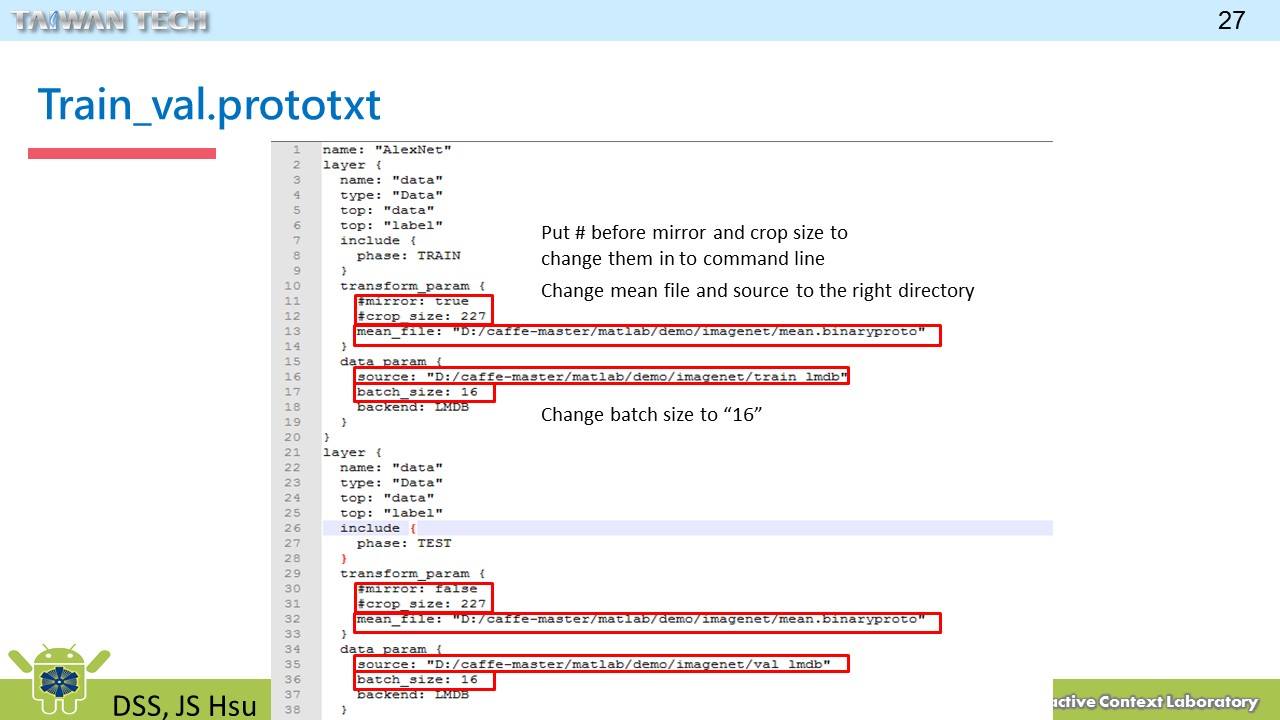
- 我們會在
mean_file參數中,放上mean.binaryproto檔案的路徑。 - 在
source參數中,分別放上img_train_lmdb與img_test_lmdb資料夾的路徑。 - 如果之後在訓練時,出現 GPU 記憶體不足的情況,請降低
batch_size的大小。
ResNet 與 SENet 的訓練設定檔案,分別為ResNet_solver_101.prototxt與SE-ResNet_solver_101.prototxt。
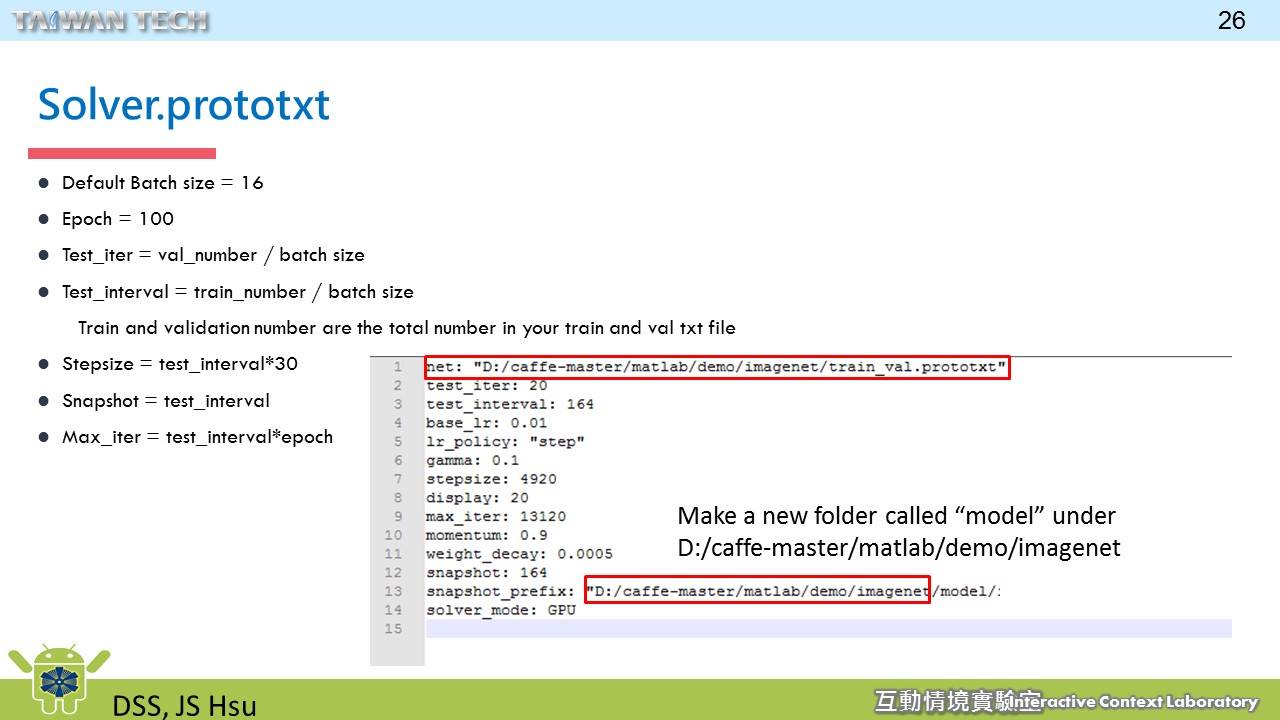
- 我們會在
net參數中,放上剛剛介紹的網路結構檔案路徑。 - 剩下參數請依照圖示進行調整。當然 Solver 有非常多的參數可以設定,更多的範例請參考這邊。
開始跑訓練的檔案是Step4_train.bat。
- 裡面有三個參數,第一個是 caffe.exe 的路徑,這東西在桌面上的
caffe-windows-ms資料夾中,所以我們才在最一開始特別提醒不要去動這個資料夾;第二個是train指令;第三個是要用來訓練的訓練設定檔案,也就是 Solver 檔。 - 開始訓練時,如果遇到訓練暫停(使用鍵盤組合鍵 Ctrl + C)或是迭代次數到達了 Solver 中的
snapshot次數,網路就會在model資料夾中儲存caffemodel與solverstate權重檔案,這兩個檔案將可用在「恢復訓練」或是「測試」階段。
使用Step4_resume_train.bat恢復之前跑到一半的訓練。
- 如果要恢復之前暫停的訓練,請在 .bat 檔中設定
--snapshot參數為「.solverstate 檔案的路徑」並雙擊即可。
測試篇
網路評估工具 Classification.ipynb
因為後來在實驗中發現,Caffe 內建的測試彈性並不大,所以Step5_test.bat檔案我們就不用了,改用 Python 程式來進行測試。
- 首先,請打開 Anaconda,將
Applications on切換為「Caffe」並執行 Jupyter Notebook。 - 開啟網頁視窗後,點擊
ResNet資料夾當中的Classification.ipynb檔案。
Setup & Functions
- 第一段的 Setup & Functions 部份是在進行初始化,讓我們的程式可以全自動地計算網路識別的 Precision、Recall、F1-score、Specificity 等參數。
- 這部分只有幾個地方可能需要修改:
- 首先是在
#----- image_testing -----段落的 for 迴圈中,將「4501」更改為你的「測試影像數 + 1」的數字。 - 接著在同一個段落中,將
image = caffe.io.loade_image(...)當中的路徑,更改為存放「測試影像」的路徑。 - 如果你想知道系統將哪幾張影像辨識錯誤,請將
#----- score_measure -----段落中間兩個print函式的註解關閉。 - 如果你想繪製混淆矩陣,請在同個段落中,將最後四行的註解關掉。
- 如果你想顯示 F1-score 未達 100% 的排藥名稱與分數,請在最下面的
#----- Average -----段落,將最後兩行註解關閉。
- 首先是在
F1-score measure
- 在這一段程式中,我們可以透過 for 迴圈來大量測試數個模型網路的識別效果。
- 首先設定每一類別的測試影像張數
catCount,接著設定model資料夾中,測試用的權重檔案迭代次數:step代表每個 model 間的迭代次數差距;begin代表第一個權重檔的迭代次數;end代表最後一個權重檔的迭代次數。 - 接著在
model_def放置網路結構檔案路徑;在model_weights放置權重檔案路徑;在mu_file放置影像均值檔案路徑。 - 執行以後,就會列出每個模型的測試評估分數。
Other measurements
- 這部分的測試包含了 Top-1、Top-5、Softmax 分佈以及機率分佈圖。
- 在最前面的
#----- Variables -----設定為變數後,就可以逐一執行後面的程式。